Conceptual clustering
Conceptual clustering is a machine learning paradigm for unsupervised classification developed mainly during the 1980s. It is distinguished from ordinary data clustering by generating a concept description for each generated class. Most conceptual clustering methods are capable of generating hierarchical category structures; see Categorization for more information on hierarchy. Conceptual clustering is closely related to formal concept analysis, decision tree learning, and mixture model learning.
Contents |
Conceptual clustering vs. data clustering
Conceptual clustering is obviously closely related to data clustering; however, in conceptual clustering it is not only the inherent structure of the data that drives cluster formation, but also the description language which is available to the learner. Thus, a statistically strong grouping in the data may fail to be extracted by the learner if the prevailing concept description language is incapable of describing that particular regularity. In most implementations, the description language has been limited to feature conjunction, although in COBWEB (see "COBWEB" below), the feature language is probabilistic.
List of published algorithms
A fair number of algorithms have been proposed for conceptual clustering. Some examples are given below:
- CLUSTER/2 (Michalski & Stepp 1983)
- COBWEB (Fisher 1987)
- CYRUS (Kolodner 1983)
- GALOIS (Carpineto & Romano 1993),
- GCF (Talavera & Béjar 2001)
- INC (Hadzikadic & Yun 1989)
- ITERATE (Biswas, Weinberg & Fisher 1998),
- LABYRINTH (Thompson & Langley 1989)
- SUBDUE (Jonyer, Cook & Holder 2001).
- UNIMEM (Lebowitz 1987)
- WITT (Hanson & Bauer 1989),
More general discussions and reviews of conceptual clustering can be found in the following publications:
- Michalski (1980)
- Gennari, Langley, & Fisher (1989)
- Fisher & Pazzani (1991)
- Fisher & Langley (1986)
- Stepp & Michalski (1986)
Example: A basic conceptual clustering algorithm
This section discusses the rudiments of the conceptual clustering algorithm COBWEB. There are many other algorithms using different heuristics and "category goodness" or category evaluation criteria, but COBWEB is one of the best known. The reader is referred to the bibliography for other methods.
Knowledge representation
The COBWEB data structure is a hierarchy (tree) wherein each node represents a given concept. Each concept represents a set (actually, a multiset or bag) of objects, each object being represented as a binary-valued property list. The data associated with each tree node (i.e., concept) are the integer property counts for the objects in that concept. For example (see figure), let a concept 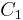 contain the following four objects (repeated objects being permitted).
contain the following four objects (repeated objects being permitted).
[1 0 1][0 1 1][0 1 0][0 1 1]
The three properties might be, for example, [is_male, has_wings, is_nocturnal]. Then what is stored at this concept node is the property count [1 3 3], indicating that 1 of the objects in the concept is male, 3 of the objects have wings, and 3 of the objects are nocturnal. The concept description is the category-conditional probability (likelihood) of the properties at the node. Thus, given that an object is a member of category (concept) , the likelihood that it is male is 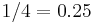 . Likewise, the likelihood that the object has wings and likelihood that the object is nocturnal or both is
. Likewise, the likelihood that the object has wings and likelihood that the object is nocturnal or both is 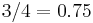 . The concept description can therefore simply be given as
. The concept description can therefore simply be given as [.25 .75 .75], which corresponds to the -conditional feature likelihood, i.e., 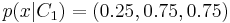 .
.
The figure to the right shows a concept tree with five concepts. 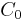 is the root concept, which contains all ten objects in the data set. Concepts and
is the root concept, which contains all ten objects in the data set. Concepts and 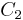 are the children of , the former containing four objects, and the later containing six objects. Concept is also the parent of concepts
are the children of , the former containing four objects, and the later containing six objects. Concept is also the parent of concepts 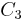 ,
, 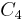 , and
, and 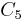 , which contain three, two, and one object, respectively. Note that each parent node (relative superordinate concept) contains all the objects contained by its child nodes (relative subordinate concepts). In Fisher's (1987) description of COBWEB, he indicates that only the total attribute counts (not conditional probabilities, and not object lists) are stored at the nodes. Any probabilities are computed from the attribute counts as needed.
, which contain three, two, and one object, respectively. Note that each parent node (relative superordinate concept) contains all the objects contained by its child nodes (relative subordinate concepts). In Fisher's (1987) description of COBWEB, he indicates that only the total attribute counts (not conditional probabilities, and not object lists) are stored at the nodes. Any probabilities are computed from the attribute counts as needed.
The COBWEB language
The description language of COBWEB is a "language" only in a loose sense, because being fully probabilistic it is capable of describing any concept. However, if constraints are placed on the probability ranges which concepts may represent, then a stronger language is obtained. For example, we might permit only concepts wherein at least one probability differs from 0.5 by more than  . Under this constraint, with
. Under this constraint, with 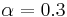 , a concept such as
, a concept such as [.6 .5 .7] could not be constructed by the learner; however a concept such as [.6 .5 .9] would be accessible because at least one probability differs from 0.5 by more than . Thus, under constraints such as these, we obtain something like a traditional concept language. In the limiting case where 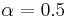 for every feature, and thus every probability in a concept must be 0 or 1, the result is a feature language base on conjunction; that is, every concept that can be represented can then be described as a conjunction of features (and their negations), and concepts that cannot be described in this way cannot be represented.
for every feature, and thus every probability in a concept must be 0 or 1, the result is a feature language base on conjunction; that is, every concept that can be represented can then be described as a conjunction of features (and their negations), and concepts that cannot be described in this way cannot be represented.
Evaluation criterion
In Fisher's (1987) description of COBWEB, the measure he uses to evaluate the quality of the hierarchy is Gluck and Corter's (1985) category utility (CU) measure, which he re-derives in his paper. The motivation for the measure is highly similar to the "information gain" measure introduced by Quinlan for decision tree learning. It has previously been shown that the CU for feature-based classification is the same as the mutual information between the feature variables and the class variable (Gluck & Corter, 1985; Corter & Gluck, 1992), and since this measure is much better known, we proceed here with mutual information as the measure of category "goodness".
What we wish to evaluate is the overall utility of grouping the objects into a particular hierarchical categorization structure. Given a set of possible classification structures, we need to determine whether one is better than another.
Incremental structure learning
Order dependence
External links
References
- Biswas, G.; Weinberg, J. B.; Fisher, Douglas H. (1998). "Iterate: A conceptual clustering algorithm for data mining". IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews 28: 100–111.
- Carpineto, C.; Romano, G. (1993). "Galois: An order-theoretic approach to conceptual clustering". Proceedings of 10th International Conference on Machine Learning, Amherst. pp. 33–40.
- Fisher, Douglas H. (1987). "Knowledge acquisition via incremental conceptual clustering". Machine Learning 2 (2): 139–172. doi:10.1007/BF00114265.
- Fisher, Douglas H.; Langley, Patrick W. (1986). "Conceptual clustering and its relation to numerical taxonomy". In Gale, W. A. (Ed.). Artificial Intelligence and Statistics. Reading, MA: Addison-Wesley. pp. 77–116.
- Fisher, Douglas H.; Pazzani, Michael J. (1991). "Computational models of concept learning". In Fisher, D. H.; Pazzani, M. J.; Langley, P. (Eds.). Concept Formation: Knowledge and Experience in Unsupervised Learning. San Mateo, CA: Morgan Kaufmann. pp. 3–43.
- Gennari, John H.; Langley, Patrick W.; Fisher, Douglas H. (1989). "Models of incremental concept formation". Artificial Intelligence 40: 11–61. doi:10.1016/0004-3702(89)90046-5.
- Hanson, S. J.; Bauer, M. (1989). "Conceptual clustering, categorization, and polymorphy". Machine Learning 3 (4): 343–372. doi:10.1007/BF00116838.
- Jonyer, I.; Cook, D. J.; Holder, L. B. (2001). "Graph-based hierarchical conceptual clustering". Journal of Machine Learning Research 2: 19–43. doi:10.1162/153244302760185234.
- Lebowitz, M. (1987). "Experiments with incremental concept formation". Machine Learning 2 (2): 103–138. doi:10.1007/BF00114264.
- Michalski, R. S. (1980). "Knowledge acquisition through conceptual clustering: A theoretical framework and an algorithm for partitioning data into conjunctive concepts". International Journal of Policy Analysis and Information Systems 4: 219–244.
- Michalski, R. S.; Stepp, R. E. (1983). "Learning from observation: Conceptual clustering". In Michalski, R. S.; Carbonell, J. G.; Mitchell, T. M. (Eds.). Machine Learning: An Artificial Intelligence Approach. Palo Alto, CA: Tioga. pp. 331–363.
- Stepp, R. E.; Michalski, R. S. (1986). "Conceptual clustering: Inventing goal-oriented classifications of structured objects". In Michalski, R. S.; Carbonell, J. G.; Mitchell, T. M. (Eds.). Machine Learning: An Artificial Intelligence Approach. Los Altos, CA: Morgan Kaufmann. pp. 471–498.
- Talavera, L.; Béjar, J. (2001). "Generality-based conceptual clustering with probabilistic concepts". IEEE Transactions on Pattern Analysis and Machine Intelligence 23 (2): 196–206. doi:10.1109/34.908969.